היטליסט, הוא מוצר Big Data עם אלגוריתם ייחודי שפיתחנו המשקלל את הטעם של מאות אלפי ישראלים המאזינים לשירים יום-יום בשלל פלטפורמות. זו הפעם הראשונה שגוף תקשרות ישראלי מודד את "עוצמת השירים" מכלל הפלטפורמות בזמן אמת.
מעבר לממשקי המשתמש המאפשרים לצפות בנתוני המצעד מדי שבוע, פיתחנו מערכות דאטה מתקדמות ומנגנוני איסוף נתונים בשיטות שונות כדי להצליח לאסוף בזמן אמת את נתוני האזנות של הציבור הישראלי מתחנות רדיו ומפלטפורמות דיגיטליות שונות. בנוסף לאיסוף הדאטה, פיתחנו אלגוריתם המנתח ומבצע חישובים על הנתונים שאספנו בכדי לייצר מצעד מוזיקה שבועי המתבסס על כלל נתוני האזנות של הציבור הישראלי.
משקלל את הטעם של מאות אלפי ישראלים המאזינים לשירים יום-יום בשלל פלטפורמות
זו הפעם הראשונה שגוף תקשורת ישראלי מודדד את "עוצמת השירים" מכל הפלטפורמות: תחנות הרדיו השונות, פלטפורמות מוזיקה דיגיטליות כמו יוטיוב, ספוטיפיי, אפל מיוזיק ורשתות חברתיות כמו טיקטוק. בכל העולם המצעדים תמיד התבססו על מכירות סינגלים ובשנים האחרונות על סטרימינג. בישראל מעולם לא היה מצעד אמיתי שחף ממניפולציה של המצביעים או העורכים. בשנות ה-70 וה-80 השירים דורגו על ידי המאזינים במכתבים וגלויות, בשנות ה-90 השתדרגו לטלמסר ומשנות ה-2000 מצביעים באינטרנט.

איסוף הנתונים: תחנות רדיו ועד פלטפורמות דיגיטליות
האתגר הראשון שהתמודדנו איתו היה איך לאסוף את כל נתוני השירים וההאזנות מהפלטפורמות השונות. כבר בתחילתו של הפרויקט הבנו שכדי לאסוף כל כך הרבה נתונים ממקורות שונים מצריך תכנון וחשיבה שונה לגבי מבנה הנתונים ואיך לשמור אותם, בתהליך מיפינו את סוגי הנתונים מהפלטפורמות השונות, תכננו את מבנה בסיס הנתונים כך שנוכל לשמור את הנתונים בנפרד לכל פלטפורמה כאשר הערך המרכזי שלנו היה "לשמור כמה שיותר" ונחשוב אח"כ איך לנתח את הדאטה.
החיבור וסוגי הנתונים בין תחנות הרדיו המסורתיות לבין מוצרי סטרימינג דיגיטליים הכריח אותנו לייצר סוגים שונים של טבלאות ומבנה הנתונים וגם צורך בפיתוח של מערכת "שרידה" המסוגלת לאסוף כמויות דאטה גדולות.
בעזרת כלים שונים אנו אוספים "השמעות" מתחנות הרדיו בזמן אמת ומדי יום - ובעצם שומרים אל בסיס הנתונים שיצרנו את ההשמעות השונות ברדיו. במקביל, אנו מושכים בעזרת שיטות שונות ומנגנוני API נתוני האזנות מהפלטפרומות הדיגיטליות השונות כמו יוטיוב, ספוטיפיי, אפל מיוזיק ועוד.
איסוף הנתונים מתייחס בשלב הראשון לכל פלטפורמה בנפרד, שכן כל פלטפורמה עובדת בשיטה שונה, מחלקן אנו אוספים נתוני האזנות יומיים, ומנגד מפלטפורמות אחרות אנו אוספים נתונים "מאוגדים" לכל השבוע, המבנים השונים של הדאטה הצריכו מאיתנו חשיבה רבה גם בתהליך איסוף הנתונים וכמובן בתהליך של ניתוח המידע שאספנו.
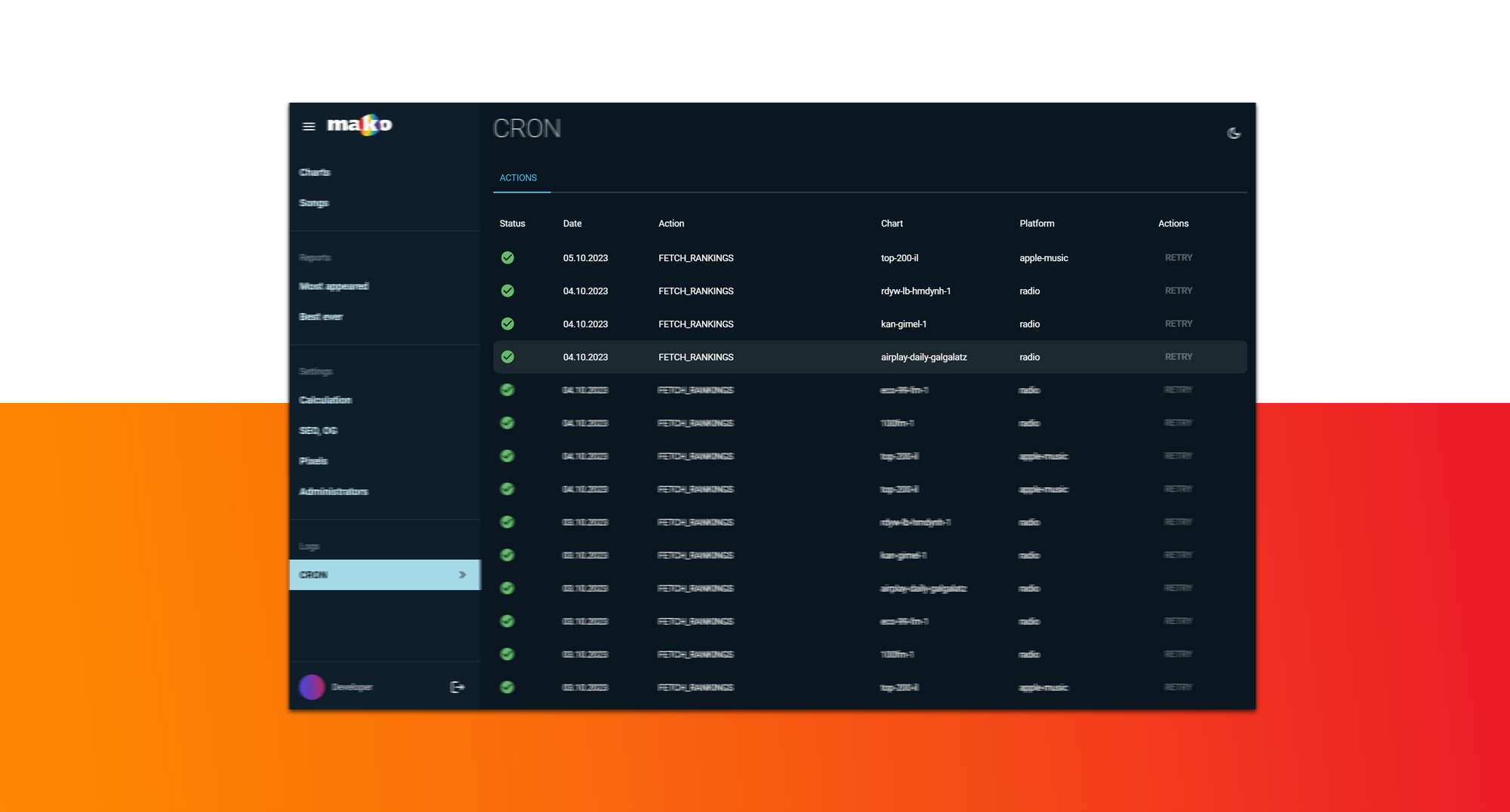
כדי להבטיח מינימום תקלות בתהליכי איסוף הנתונים, הקמנו מערכת cron job service שמריצה תהליכי איסוף שונים בצורה אוטומטית ואף בצורה חזרתית בכל שעה עגולה, ובכדי להבטיח שאנו אוספים את כל המידע שנרדש, אנו מבצעים תהליך חזרתי שרץ בכל סוף יום ומושך את הדאטה מחדש - בעצם סוג של תהליך אימות שיש לנו את כל המידע היומי שאנחנו צריכים כדי להצליח לייצר מצעד שבועי.
יצירת המצעד: ניתוח הנתונים והאלגוריתם
האתגר הנוסף והמרכזי בהקמת המוצר הדיגיטלי של היטליסט הוא תהליך יצירת המצעד שבועי, ובמילים אחרות, איך אנחנו מייצרים מצעד שבועי מכל הנתונים שאספנו, כאשר יש לנו נתונים במבנים שונים, חלקם יומיים, חלקם שבועיים ומפלטפורמות שונות שלא תמיד מדד החישבות שלהם זהה.
תהליך החשיבה נעשה בשיתוף הצוות הטכנולוגי שלנו ובהובלה של עורכי המוזיקה ומנהלי המוצר ב-mako', שם עלו שאלות איך לזקק מכלל הנתונים מצעד אמיתי ואיך לייצר נוסחה או בשפה המקצועית "אלגוריתם" שבסופו נוכל להציג מצעד שבועי המכיל את מאה השירים המושמעים ביותר ע"י הציבור הישראלי.
בתהליך הזיקוק והחשיבה הצלחנו לייצר פתרונות לשאלות מורכבות שעלו כמו איך מתייחסים להשמעת רדיו של שיר כלשהו בשעות ה"פריים טיים" לעומת שעות "שקטות"?, מה החשיבות של השמעה בפלטפורמה דיגיטלית כזו או אחרת?, ואיך בכלל מתמודדים עם שירים "מקודמים" בצורה "מלאכותית" בזירות הדיגיטל כדי שלא יהיו פקטור משמעותי על המצעד השבועי.
לבסוף, כאשר נבחרה הנוסחה הנכונה ע"י הצוות של מאקו, ועוד לפני שהתחלנו לכתוב קוד, ניסינו את הנוסחה ביחד עם מאקו על נתונים אמיתיים שאספנו, על גבי קבצי אקסל וחישובים רבים שביצענו מדי שבוע עוד לפני שיצאנו לפיתוח. התהליך הזה נתן לנו את האפשרות לשפר את הנוסחה, לזקק אותה ולהגיע לשלב פיתוח האלגוריתם מוכנים יותר.

איך מזהים שירים מפלטפורמות שונות? ממשק הניהול ומצבי קצה
כדי לאפשר לעורכי המוזיקה של מאקו לוודא שכלל המערכות עובדות בצורה תקינה, הקמנו ממשק ניהול ודשבורד המציג את נתוני איסוף הנתונים וסיכום לוגים של מערכות cron job service, כך ניתן להבחין בזמת אמת אילו נתונים המערכת משכה והאם יש תקלה כלשהי בתהליך המשיכה.
הבעיה המרכזית שהיינו צריכים לפתור היא היכולת להבין ולאפשר למערכת לחבר בין שירים מפלטפורמות שונות, במילים אחרות, איך לזהות ששיר כלשהו מספוטיפי זה אותו השיר מיוטיוב, שכן לעיתים האמנים משחררים את השירים עם "כיתוב" שונה בשם השיר או לעיתים עם כיתוב זהה אבל גרסאות השיר לא זהות כלל ובעצם יש להתייחס לשירים בנפרד.
השלב הראשון אנו מזהים את השירים ע"י מזהה יחודי לכל שיר שפלטפורמות הדיגיטליות מספקות ובעצם מצליבים את הנתונים של אותו השיר מכל הפלטפורמות, מנגד לעיתים רבות קיימים שירים שמגיעים עם מספר מזהה שונה מכל פלטפורמה למרות שמדובר על אותו השיר.
כדי לאפשר להתמודד עם סיטואציה כזו, פיתחנו מממשק יחודי לעורכי המוזיקה של מאקו המאפשר להם לקבל את כל השירים שהמערכת חושבת שיתכן שזה אותו שיר - כך עורכי מאקו יכולים לעבור על "רשימת המיוחדים" שהמערכת שלנו חושבת שהפלטפורמות הדיגיטליות פספסו ובעצם מאפשרת לעורכי מאקו לחבר בין השירים במערכת שלנו ולהצליב את הנתונים כדי להתייחס לכמה שירים שהגיעו עם מזהה שונה ממקורות שונים כשיר אחד אצלנו.